自己紹介¶
- 三浦 耕生(こうき)
- 大学院生、ロボット工学専攻
- TechAcademyのジュニアメンター
- IBM Champion 2020 ← New
- Twitter: @k_miura_io
- Facebook: koki.miura05
スライドのリンク¶

※このスライドはjupyter-notebookを使用しています
In [3]:
print("Hello World")
さて、本題です¶
前回までのあらすじ¶
- kickstarterでOpen MVを買ったので遊んでみた
- 小さいのに顔認識がサクサク動いて面白かった

でその翌日¶
東京でイベントにてブース出展¶
- 朝一の新幹線で東京で1日IBMのブースでお手伝い(詳しくは懇親会で)
- その帰りに久々に秋葉原を散策してたらM5Stick-Vを発見
- 前から気になってたしつい買ってしまった

というわけで¶

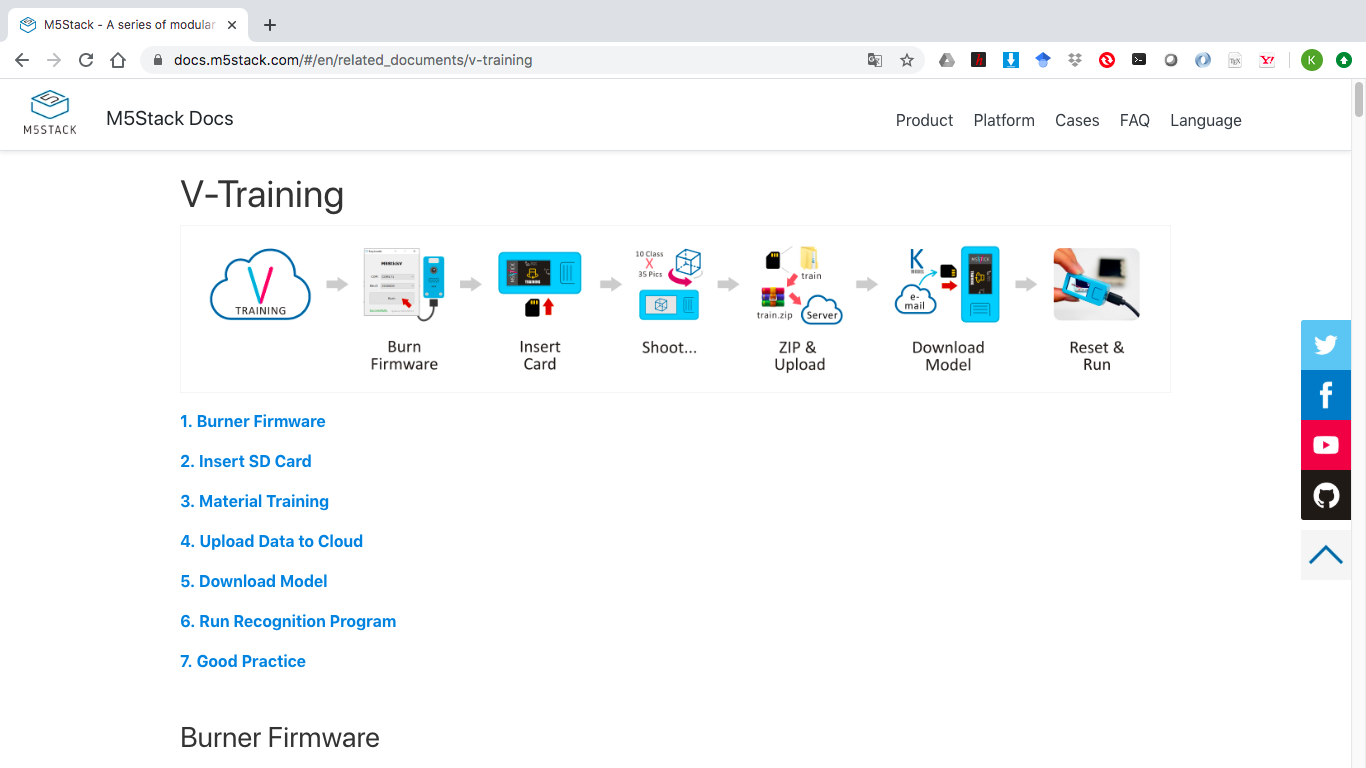
どうやらM5Stick-V用のモデルを作成するサイトがあるらしい¶
- その名もV-Training
- トレーニング用のファームウェアで画像を撮影して、サイトにアップロードすると学習モデルがメールで送られ、自作の画像分類機を簡単にできるらしい
- しかも無料
使ってみた¶
その前に今回のネタ¶
- 最近カルロス・ゴーンが何かと話題になっている
- カルロス・ゴーンってMr.Beanと顔がよく似ている
- この2人の顔を識別してみよう

データ作成¶
- スクレイピングでgoogleの画像検索で出てきた画像を取得
- V-Traningを使う場合は1クラスあたり最低35枚の画像が必要
- 最大10クラスを学習させることが可能
In [ ]:
import argparse
import json
import os
import urllib
from bs4 import BeautifulSoup
import requests
from termcolor import cprint
__version__ = "1.0.0"
Let's Take Photo¶
- そのまま学習させてもいいけど、M5目線の画像を学習したいので、M5Stick-Vを撮影して学習
- データ作成をするためのプログラムはV-TraningのサイトからダウンロードしてSDカードに保存して動かす
- とりあえず最低量の35枚の画像を収集

画像データをアップロード¶
- 専用のサイトへSDに保存されたデータセットを圧縮してアップロード
- アップロードするとステータスIDを付与されて裏側で学習される
- 学習が完了するとメールアドレスに学習したモデルと実行用のコードをセットで送られる
- ついでに学習結果も画像データで添付される
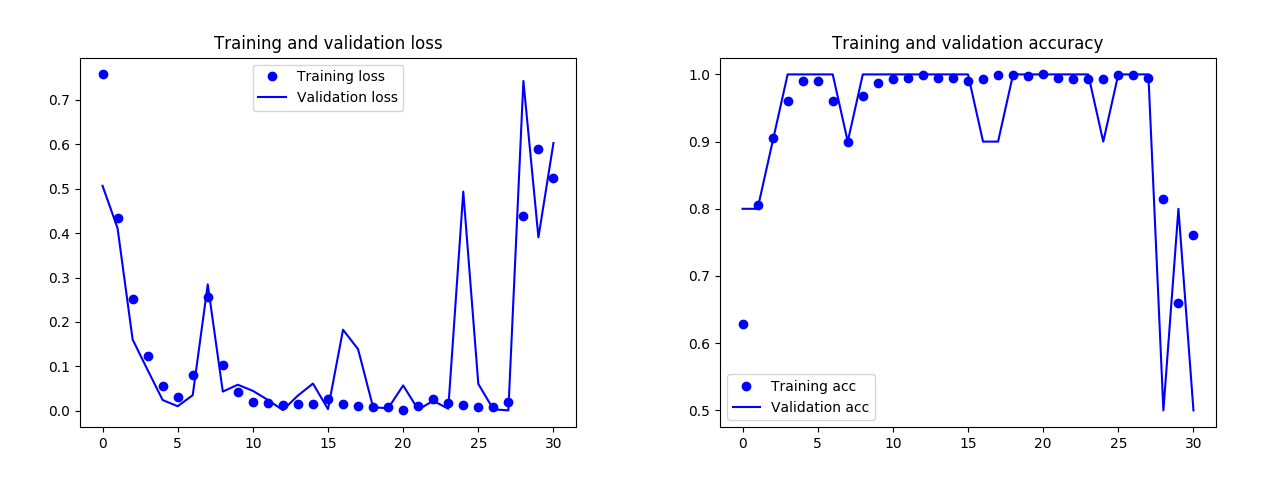
1回目の学習結果¶
- データの質が悪い&量が少ないせいで精度が悪かった
- 「もう1回送ったほうがいいよ」と一言アドバイス
(余計なお世話) - 35枚の画像では精度がでるような仕様ではないようだ
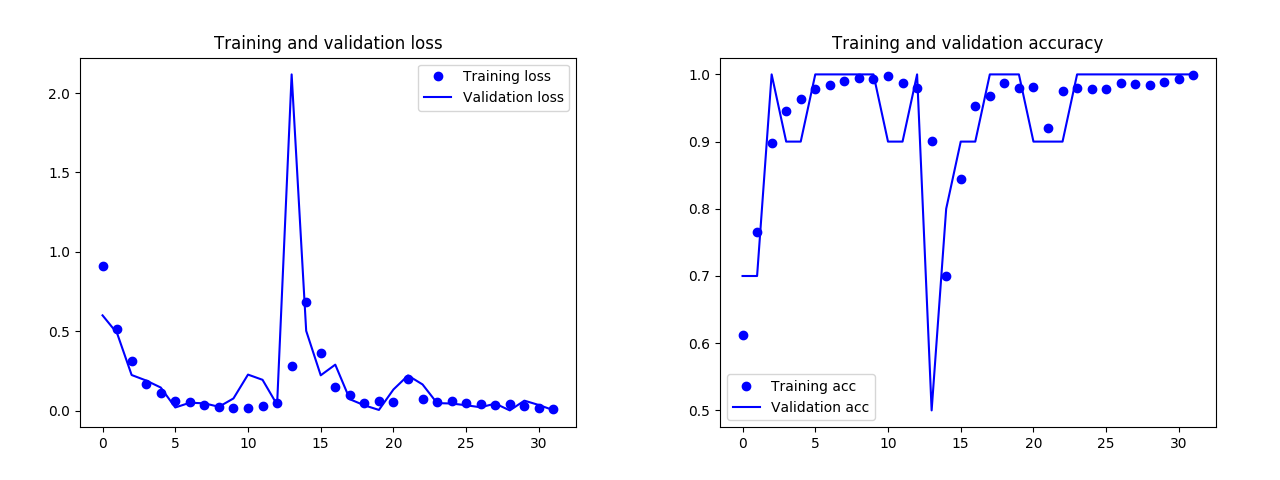
もう一度データを用意¶
- 今度は画像を100枚用意して撮影
- もちろんキーワードと関係ない画像も含まれているので実質学習に使えたのは60枚程度
- あとは単純に疲れた(笑)
デモ¶
うまくいかなときのデモ動画w¶

In [ ]:
##ソースコード
import image
import lcd
import sensor
import sys
import time
import KPU as kpu
from fpioa_manager import *
import KPU as kpu
lcd.init()
lcd.rotation(2)
try:
from pmu import axp192
pmu = axp192()
pmu.enablePMICSleepMode(True)
except:
pass
try:
img = image.Image("/sd/startup.jpg")
lcd.display(img)
except:
lcd.draw_string(lcd.width()//2-100,lcd.height()//2-4, "Error: Cannot find start.jpg", lcd.WHITE, lcd.RED)
In [ ]:
task = kpu.load("/sd/model.kmodel")
labels=["Mr.bean","Ghosn"] #You can check the numbers here to real names.
sensor.reset()
sensor.set_pixformat(sensor.RGB565)
sensor.set_framesize(sensor.QVGA)
sensor.set_windowing((224, 224))
sensor.run(1)
lcd.clear()
while(True):
img = sensor.snapshot()
fmap = kpu.forward(task, img)
plist=fmap[:]
pmax=max(plist)
max_index=plist.index(pmax)
a = lcd.display(img)
if pmax > 0.95:
lcd.draw_string(40, 60, "Accu:%.2f Type:%s"%(pmax, labels[max_index].strip()))
print("Accu:%.2f Type:%s"%(pmax, labels[max_index].strip()))
a = kpu.deinit(task)
まとめ¶
- V-Traningを使えば簡単に画像分類器を動かせる
- 小さいのにサクサク動く(本体のディスプレイでもカクつかない)
- 送信したデータが学習しなかったり、1日かかって結果が返答されるのでサーバの動作は安定していない
- メールで送られたコードはシンプルで動作が安定している
- 今年はハードウェア×AIの話を進めたい